|
|
|
|
|
|
In Part 1, the key functions in our analysis of the light bulb data were data were
and its derivative,
For a general continuous distribution, the distribution function F(t) describes the probability that a randomly selected data item will have a value less than t. (For light bulbs, "value" meant "lifetime.") Thus, the probability of a data value lying between t = a and t = b is F(b) - F(a). As we did with the light bulb data, we define the probability density function f(t) to be the derivative of the distribution function. So by the Fundamental Theorem of Calculus, we also have that the probability of a data value lying between t = a and t = b is
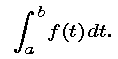
Our goal in modeling the distribution of given set of data is to find either an appropriate distribution function F or a an probability density function f. If F(t) is known, we find f(t) by differentiation. On the other hand, if f(t) is known, we find F(t) as a particular antiderivative of f(t), the one that has value 0 at the left end of the domain. Thus, a probability distribution can be specified by either its distribution function or its probability density function.
Arguing just as we did in Part 1, we define the expected value (also called average value) of a large data set distributed with density function f to be
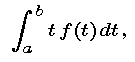
Different classes of data have different types of distributions and correspondingly different distribution and density functions. The distribution function F(t) = 1 - e - rt is called an exponential distribution, and its derivative f(t) = re - rt is called an exponential density. This model is the starting point for the study of reliability theory, which is useful for describing, among other things, failure times for electrical and electronic components such as chips in computers, batteries in toy rabbits, and bug zappers in backyards.
In this part we study two more types of distributions and their density functions. The first of these is the Cauchy distribution (pronounced ko-SHEE), which may be defined by the Cauchy probability density function:
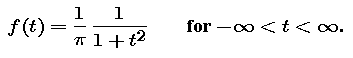
Suppose you have a spinner from a board game that randomly picks a value between 0 and 4, and you further subdivide the spinner into tenths of units. Thus you can decide whether the result of a spin is, say, greater than 2.3 and less than 3.6. We assume that this is a fair spinner -- for example, the result of a spin is as likely to give a value greater than 2 as a value less than 2. More generally, given two intervals of equal length, the probability of landing in one is the same as that for landing in the other. We suppose that we have a data set that consists of the numerical results from a large number of spins.
for t greater than or equal to 0 and less than or equal to 4.
|
|
|
| modules at math.duke.edu | Copyright CCP and the author(s), 1999 |